
빅데이터 전문가 되기
로지스틱 회귀분석 (Logistic Regression) 본문
로지스틱 회귀 모델을 이용하여 검증 및 통계 분석을 해보겠습니다.
저는 도시 양극화 지수라는 데이터를 임의로 만들어 분석하였습니다.
전국을 100으로 기준하여 상대 지표로 계산했으며, 도시 양극화에 영향을 미칠 수 인자를 설정하였습니다.
여기서, 전국 평균 데이터에서 격차가 많이 날수록 양극화일 확률이 높아집니다.
target : 도시양극화면 1, 아니면 0
<경제적 영역>
jb : 주택보급률
ahr : 노후주택비율
sp : 시군구의 1인당 소비금액 격차
ap : 시군구의 주택 매매가격 격차
grdp : 시군의 지역내총생산 격차
gj : 경제활동참가율
go : 고용률
cgo : 15~64세 고용률
sup : 실업률
<사회적 영역>
pits : 어린이집 및 유치원 서비스권역 내 영유아인구 비율
pses : 초등학교 서비스권역 내 학령인구 비율
hos : 병원 서비스권역 내 인구 비율
psap : 주차장 서비스권역 내 인구 비율
pls : 도서관 서비스권역 내 인구 비율
ppsp : 공공체육시설 서비스권역 내 인구 비율
이 때, 가설을 하나 세우겠습니다.
- 귀무가설 : 경제적 영역과 사회적 영역이 도시 양극화에 유의미한 영향을 미치지 않는다.
- 대립가설 : 경제적 영역과 사회적 영역이 도시 양극화에 유의미한 영향을 미친다.
👉 데이터 확인
import pandas as pd
# 데이터 불러오기
data = pd.read_csv('test.csv', encoding='cp949')
data.head()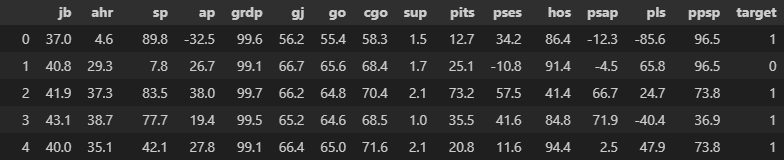
# 데이터 Null값 확인하기
data = data.fillna()
data.isna().sum()
- 데이터에 Null값이 있는 경우 상황에 따라 열을 제거해주거나, median 값으로 대체해줄 수 있습니다.
👉 상관관계 및 다중공선성 확인
# 데이터프레임에서 상관 계수 계산
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.family']='sans-serif'
plt.rcParams['font.sans-serif']= ['Arial']
corr_matrix = data.corr()
# 상관 관계 히트맵 시각화
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')
- 경제활동참가율(gj), 고용률(go), 15~64세 고용률(cgo)은 서로 상관관계가 높으므로 변수를 제거해줍니다.
# 데이터에서 상관관계, 다중공선성이 있는 변수 제거
from statsmodels.stats.outliers_influence import variance_inflation_factor
X = data.drop(['target','go','cgo','jb','grdp','gj'], axis=1)
# 각 변수의 VIF 값을 계산
vif = pd.DataFrame()
vif["Feature"] = X.columns
vif["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
# 결과 출력
print(vif)
- VIF가 10이상이면 다중공선성이 높다고 판단되어 모델의 성능이 저하될 수 있습니다.
: 따라서 10이상의 변수인 GRDP(grdp), 주택보급률(jb)는 제거해줍니다.
👉 Min-Max 정규화
# target 열을 제외한 열 선택
import statsmodels.api as sm
from sklearn.preprocessing import StandardScaler
data_vif = data[['target','ap','pits','pses','ppsp']]
data_vif_normalize = data_vif.columns[data_vif.columns != 'target']
# Min-Max 정규화 함수
normalize = lambda x: (x - x.min()) / (x.max() - x.min())
# # 선택한 열에 대해 정규화 수행
normalized_data = data_vif[data_vif_normalize].apply(normalize)
# 0인 값 최솟값으로 대체
for column in data_vif_normalize:
min_value = normalized_data[column].min()
data_vif[column] = normalized_data[column].replace(0, min_value)- 로지스틱 회귀 모델은 0인 값이 있으면 적용시킬 수 없습니다.
정규화를 진행하거나, 그전의 값에서 0의 값이 있으면 최솟값으로 대체해줍니다.
👉 로지스틱 회귀모델 학습
# 로지스틱 회귀분석을 위한 독립변수와 종속변수 분리
X = data_vif.drop('target', axis=1)
y = data_vif['target']
# 상수(intercept) 열 추가
X = sm.add_constant(X)
# 로지스틱 회귀모델 학습
logit_model = sm.Logit(y, X)
result = logit_model.fit(method='newton')
# 회귀분석 결과 요약
summary = result.summary()
print(summary)
- 후진 제거법으로 p-value가 0.05 이상인 변수들을 제거해줍니다.
- 로지스틱 회귀 분석에서는 이항 분류 문제를 다루며, 종속변수가 이항형이므로 R-squred가 의미가 없습니다.
(단, R-squred는 선형회귀분석에서는 지표)
- Log-Likelihood (로그 우도) : 모델의 적합도를 측정하는 데 사용
로지스틱 회귀모델을 학습시킬 때 method를 newton으로 하여 우도를 최대화합니다.
- LLR p-value : 로그 우도의 p-value로 0.05이하이므로 유의미하다고 볼 수 있습니다.
👉 Wald 검정/ F-test
import scipy.stats as stats
# 회귀계수의 t-test
t_values = result.tvalues
p_values_t = result.pvalues
# 회귀계수의 z-test
z_values = result.params / result.bse
p_values_z = 2* (1- stats.norm.cdf(np.abs(z_values)))
# 회귀계수의 f-test
# 로그 우도비를 사용하여 F-value 계산
f_value = result.llr
df_num = result.df_model
df_den = result.df_resid
p_value_f = 1-stats.f.cdf(f_value, df_num, df_den)
#결과 출력
for i, var in enumerate(X.columns):
print("Variable:", var)
print("t-value:", t_values[i])
print("p-value (t-test):", p_values_t[i])
print("p-value (z-test):", p_values_z[i])
print()
print("F-value:", f_value)
print("p-value (F-test):", p_value_f)
- Wald 검정(t-test) : 각 독립변수의 계수가 통계적으로 유의미한지 평가
p-value값이 모두 0.05이하로 변수들이 모두 유의미하다고 볼 수 있습니다.
- F-test : 전체 모델의 유의성을 평가하는데 사용
F-value 값이 클수록 모델의 유의한 예측 능력을 가지며, 값이 97로 예측 성능이 높다고 볼 수 있습니다.
또한, p-value가 0.05이하로 F-value의 값이 유의미하다고 볼 수 있습니다.
👉 모델의 통계적 유효성과 적합도 평가
#AIC, BIC 계산
aic = result.aic
print("AIC:", aic)
bic = result.bic
print("BIC:",bic)
- AIC, BIC : 통계 모델의 상대적인 품질을 평가하기 위한 지표
모델의 적합도와 복잡도를 고려하여 계산하며 낮을수록 모델의 예측 성능이 좋다고 판단한다.
- 여러 모델을 적용했을 때 상대적으로 AIC와 BIC가 낮은 값인 모델을 사용하는게 좋습니다.
👉 카이제곱 검정
from scipy.stats import chi2_contingency
model_chi2 = result.llr_pvalue
print("Model Chi-squre test statistic:", result.llr_pvalue)
print("Model p-value:", model_chi2)
print()
- 카이제곱 검정은 Wald와 마찬가지로 전체 모델의 유의성을 평가하는데 사용합니다.
- Chi-squre statistic : 모델이 관찰된 데이터와 얼마나 잘 일치하는가?
값이 높을수록 독립변수와 종속변수 간의 관련성이 큽니다.
- p-value : 독립변수와 종속변수 간의 관련성에 대한 유의확률
유의확률이 0.05 이하이므로 귀무가설을 기각, 대립가설을 채택합니다.
→ 따라서, 경제적 영역과 사회적 영역이 도시 양극화에 유의미한 영향을 미친다고 판단할 수 있습니다.
👉 모델의 분류 성능 확인
from sklearn.metrics import accuracy_score
from sklearn.metrics import log_loss
from sklearn.metrics import precision_score, recall_score, f1_score
#예측값 계산
y_pred_proba = result.predict(X)
y_pred = (y_pred_proba > 0.5).astype(int)
#로그 손실 계산
loss = log_loss(y, y_pred_proba)
#정확도 계산
accuracy = accuracy_score(y, y_pred)
#정밀도 계산
precision = precision_score(y, y_pred)
#재현율 계산
recall = recall_score(y, y_pred)
#F1 score 계산
f1 = f1_score(y, y_pred)
print("로그손실:",loss)
print("정확도:", accuracy)
print("정밀도:", precision)
print("재현율:", recall)
print("F1 스코어", f1)
- 저는 검증만을 준비한 것이라 분류 모델의 성능을 확인할 필요는 없지만, 머신러닝을 돌릴 때는 필요합니다.
- 로그손실, 정확도, 정밀도, 재현율, F1 Score는 분류 성능을 평가하는 지표입니다.
- 로그손실 : 모델의 예측 결과와 실제결과 간의 차이를 나타내는 지표
0에 가까울수록 모델의 예측이 정확합니다.
- 정확도 : 전체 샘플 중 올바르게 예측한 샘플의 비율을 나타내는 지표
1에 가까울수록 모델의 예측이 정확합니다.
- 정밀도 : positive로 예측한 샘플 중 실제로 positive인 샘플의 비율을 나타내는 지표
1에 가까울수록 실제로 positive인 샘플을 잘 찾아냅니다.
- 재현율 : 실제로 positive인 샘플 중 모델이 정확하게 positive로 예측한 샘플의 비율을 나타내는 지표
1에 가까울수록 모델이 positive인 샘플을 잘 찾아냅니다.
- F1 Score : 정밀도와 재현율의 조화 평균으로 계산되는 지표
1에 가까울수록 모델의 예측 성능이 좋습니다.
- 이 내용은 혼동 행렬을 통하여 알 수 있습니다.
- 또한, 이 모델은 분류 성능이 양호하다고 판단할 수 있습니다.
👉 오즈비 구하기
import numpy as np
np.exp(result.params)
- 주택매매가격 격차가 1이 커질수록 도시 양극화가 될 확률이 2.54e+08배 증가한다.
- 어린이집 및 유치원 서비스권역 내 영유아인구 비율의 격차가 1% 높아질수록 도시 양극화가 될 확률이 1.72e+04배 증가한다.
- 초등학교 서비스권역 내 학령인구 비율의 격차가 1% 높아질수록 도시 양극화가 될 확률이 5.72e+02배 증가한다.
- 공공체육시설 서비스권역 내 인구 비율의 격차가 1% 높아질수록 도시 양극화가 될 확률이 1.08e+02배 증가한다.
이상 로지스틱 회귀분석에서 사용할 수 있는 통계를 모두 사용해보았습니다.
'머신러닝' 카테고리의 다른 글
| 회귀분석 (Regression analysis) (0) | 2023.05.25 |
|---|---|
| 머신러닝 - LightGBM (0) | 2023.04.19 |
| 더미변수 만들기 (0) | 2023.04.19 |
| 머신러닝 입문 (0) | 2023.04.19 |
| 머신러닝 Data Leakage (0) | 2023.04.18 |


