
빅데이터 전문가 되기
머신러닝 - LightGBM 본문
👀 LightGBM 이란?
: Gradient Boosting 프레워크로 Tree 기반 학습 알고리즘 (리프 기준 분할 방식 사용)
기존의 다른 Tree기반 알고리즘과 다른 것은 수직적으로 확장하는 것입니다.
* GMB(Gradient Boosting Machine) : 틀린 부분에 가중치를 더하면서 진행하는 알고리즘

- 장점
(1) XGBoost 대비 빠른 학습과 예측 수행 시간
(2) 더 작은 메모리 사용량
- 단점
(1) 적은 데이터 세트일 경우 과적합이 발생하기 쉽다.
👉 LightGBM 하이퍼 파라미터
: LGBM의 경우 복잡한 것은 파라미터 튜닝입니다. Light GBM은 100개 이상의 파라미터를 커버하고 있기 때문입니다.
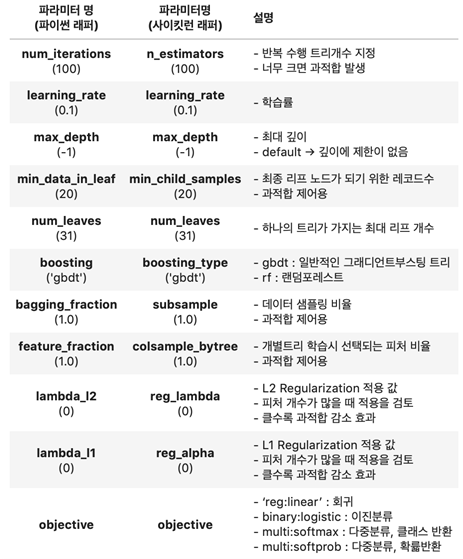
- max_depth [default = 1] : Tree의 최대 깊이. 모델 과적합을 다룰 때 사용.
( 모델의 과적합 해결 시 max_depth를 줄여야 함. )
- min_data_in_leaf [default = 20] : Leaf가 가지고 있는 최소한의 레코드 수.
( 모델이 과적합 해결 시 사용되는 파라미터)
- feature_fraction : Boosting이 랜덤포레스트일 경우 사용.
( 0.8 : Tree를 만들 때 매번 각각의 iteration 반복에서 80%를 랜덤하게 선택 )
- bagging_fraction : iteration을 돌 때 데이터의 일부를 선택하는데 트레이닝 속도를 높이고 과적합을 방지할 때 사용.
- early_stopping_round : 분석속도를 높이는데 도움 됨. 지나친 iteration을 줄이는데 도움 됨.
- lambda : regularization 정규화 함. 일반적으로 값의 범위는 0 ~ 1 사이
- min_gain_to_split : 분기하기 위해 필요한 최소한의 gain.
- max_cat_group [default =64] : 카테고리 수가 클 때, 과적합을 방지하는 분기 포인트를 찾음.
- Task : 데이터에 대해 수행하고자 하는 임무를 구체화
- application [default = regression] : 모델의 어플리케이션을 정함.
( regression : 회귀분석 / binary : 이진 분류 / multiclass : 다중 분류 )
- boosting [default = gdbt] : 알고리즘 타입 정의.
( gdlt : Traditional Gradient Boosting Decision Tree / rf : Random Forest
dart : Dropouts meet Multiple Additive Regression Trees / goss : Gradient-based One-Side Sampling )
- num_boost_round : boosting iteration 수. 일반적으로 100 이상
- learning_rate [default = 0.1] : 각각 Tree에 영향을 미치는 변수
- num_leaves [default = 31 ] : 전체 Tree의 leave 수.
- device : default 값은 cpu. gpu로 변경 가능
- metric : 모델을 구현할 때 손실을 정함.
( mae : mean absolute error / mse : mean squared error
binary_logloss : loss for binary classification / multi_logloss : loss for multi classification )
👉 하이퍼 파라미터 튜닝 방안
- num_levels의 개수를 중심으로 min_chlid_samples(min_data_in_leaf), max_depth를 함께 조정하면서 모델의
복잡도를 줄이는 것이 기본 튜닝 방안입니다.
- learning_rate를 작게 하면서 n_estimators를 크게 하는 것은 부스팅 계열 튜닝에서 가장 기본적인 튜닝 방안으로 이를
적용하는 것도 좋습니다. (단, n_estimators를 너무 크게하면 과적합으로 오히려 성능이 저하될 수 있습니다.)
- reg_lambda, reg_alpha와 같은 regularization을 적용하거나 학습 데이터에 사용할 피처의 개수나 데이터 샘플링 레코드 개수를 줄이기 위해 colsample_bytree, subsample 파라미터를 적용할 수 있습니다.
예제를 통해 lightgbm에 대해 좀 더 알아봅시다.
😄 위스콘신 유방암 예측
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, recall_score, f1_score, precision_score, roc_auc_score
from sklearn.metrics import confusion_matrix
# 위스콘신 유방함 데이터 세트 이용
dataset = load_breast_cancer()
ftr = dataset.data
target = dataset.target
# 예제 데이터 세트 중 80% 학습, 20% 테스트 데이터셋으로 분할
X_train, X_test, y_train, y_test = train_test_split(ftr, target, test_size=0.2, random_state=156)
# 트리개수는 400개로 지정
lgbm_wrapper = LGBMClassifier(n_estimators=400)
# LGBM도 XGBoost처럼 early stopping 가능
evals = [(X_test, y_test)]
lgbm_wrapper.fit(X_train, y_train, early_stopping_rounds = 100, eval_metric='logloss',
eval_set = evals, verbose = True)
preds = lgbm_wrapper.predict(X_test)
# 혼동행렬, 정확도, 정밀도, 재현율, F1, AUC 불러오기
def get_clf_eval(y_test, y_pred):
confusion = confusion_matrix(y_test, y_pred)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
F1 = f1_score(y_test, y_pred)
AUC = roc_auc_score(y_test, y_pred)
print('오차행렬:\n', confusion)
print('\n정확도: %.4f'% accuracy)
print('정밀도: %.4f' % precision)
print('재현율: %.4f' % recall)
print('F1: %.4f' % F1)
print('AUC: %.4f' % AUC)
get_clf_eval(y_test, preds)
> 오차행렬:
[[33 4]
[ 1 76]]
정확도: 0.9561
정밀도: 0.9500
재현율: 0.9870
F1: 0.9682
AUC: 0.9395# feature importance 시각화
# plot_importance()를 통해 피처 중요도 시각화
from lightgbm import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
f, ax = plt.subplots(figsize=(6,6))
plot_importance(lgbm_wrapper, max_num_features=15, ax=ax) # 상위 15개만 조회
'머신러닝' 카테고리의 다른 글
| 로지스틱 회귀분석 (Logistic Regression) (0) | 2023.06.08 |
|---|---|
| 회귀분석 (Regression analysis) (0) | 2023.05.25 |
| 더미변수 만들기 (0) | 2023.04.19 |
| 머신러닝 입문 (0) | 2023.04.19 |
| 머신러닝 Data Leakage (0) | 2023.04.18 |


