
빅데이터 전문가 되기
회귀분석 (Regression analysis) 본문
😸 회귀분석 (Regression test)이란?
- 독립변수가 종속변수에 영향을 미치는지 알아보고자 할 때 실시하는 분석방법.
- 규명된 함수식을 이용하여 설명변수들의 변화로부터 반응변수의 변화를 예측하는 분석.
👀 선형 회귀분석 (Linear Regression)
- 지도 학습 중 예측 문제에 사용하는 알고리즘
- 새로운 데이터가 들어왔을 때 어떤 값이 될지 예측하는 문제
- 설명변수와 반응변수가 연속형 변수일 때 사용 가능
( 설명변수가 범주형 변수인 경우 더미변수로 변환하여 회귀분석 적용 )
* 더미변수 변환이유?
: 패턴이 없는 변수를 패턴을 만들어주기 위하여 0과 1로 변환시키는 것
👉 단순 선형 회귀 분석
1) 선형 회귀분석 : 하나의 직선을 찾는 것 -> 이 선을 함수로 표현한 것 : 회귀식

2) 회귀선을 찾는 기준 : 최소제곱법
- 잔차 : 관측값의 y와 예측값의 y 간의 차이
- 최소제곱법 : 잔차의 제곱합이 최소가 되도록하는 직선을 회귀선으로 한다.
- 회귀식에서 a : 회귀계수 (가중치의 역할, x가 y에 얼마나 영향을 주는지 크기와 방향을 알 수 있음.),
b : 절편 ( y=ax의 회귀선을 얼마나 위, 아래로 평행이동 시킬 것인지 정함.)
👉 다중 선형 회귀 분석
- 설명변수 x가 2개 이상, 반응변수 y가 1개인 선형 회귀분석

👉 선형 회귀분석의 가설 검정
- 일반적으로 대립가설 : y=ax + b에서 회귀계수 a는 0이 아니다 (x는 y에 영향을 준다)
-> 이 가설은 개별 설명변수에 대한 가설, 회귀모델 자체의 가설 x
- 실질적인 회귀모델에 대한 유의성 검증 : F-Test
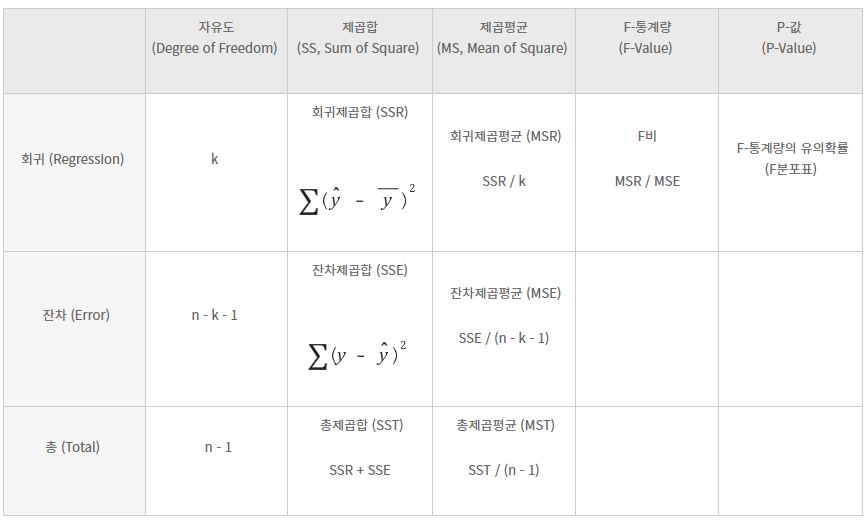
- 관측값(실제 y값) : 우리가 예측하려는 목표치
- 회귀예측값 : 회귀모델로 예측한 값
- 평균값 : 관측값 y들의 평균

- F-통계량 : 회귀제곱평균(MSR) / 잔차제곱평균(MSE)
- 회귀제곱평균(MSR) : 회귀제곱합(SSR) / 자유도(DF)
회귀로 설명할 수 있는 편차. (회귀예측값과 평균의 차이)
평균값과 회귀로 예측해서 말하는 것의 차이가 얼마나 있는지 말해주는 수치
- 잔차제곱평균(MSE) : 잔차제곱합(SSE) / 자유도(DF)
회귀로도 설명할 수 없는 잔차. (관측값과 회귀예측값의 차이)
회귀로 예측해도 좁힐 수 없는 관측값과의 차이가 얼마나 있는지 말해주는 수치
-> 즉, F-통계량 : 회귀로 좁힐 수 없는 예측 오차 대비 회귀로 인해 좁혀진 예측 오차가 얼마나 큰가 표현한 수치
( 값이 클수록 회귀모델이 유용하다. )
예시로, R을 이용하여 iris 데이터 중 Sepal.Length를 Sepal.Width로 예측해봅니다.
# 회귀모델 생성


-> 회귀모델 fit에서 F-통계량(F-Value) : 2.0744, P-Value : 0.15로 유의확률 0.05보다 크므로 fit모델이 유의하지 못하다.

👉 회귀모델의 설명력 결정계수(R^2)
- 결정계수
- 회귀제곱합(SSR) / 총제곱합(SST)
- 회귀모델의 설명력을 의미하는 수치.
- 전체 편차 중 회귀로 설명 가능한 편차가 몇 %인지 계산하겠다.
- 조정된 결정계수 (Adjusted R Square)
- 1 - 오차제곱평균(MSE) / 총제곱평균(MST)
- 설명변수 x의 개수를 고려하여 제곱합들을 자유도로 나눈 값.
👉 회귀분석의 4가지 기본 가정
1) 독립성 : 설명변수와 다른 설명변수간의 상관관계가 적다.
2) 선형성 : 설명변수와 반응변수 간의 관계 분포가 선형의 관계를 가진다.
-> 선형성을 만족하지 않는다면?
: 다른 새 변수 추가, 로그,지수 등 변수 변환, 변수 제거, 변수 선택법을 통과시킴.
3) 잔차의 등분산성 : 잔차가 특정한 패턴을 보이지 않는다.
-> 표준화 잔차 분포를 가질 경우?
: 중요한 변수가 분산 데이터에서 빠져있다는 뜻.
4) 잔차의 정규성 : 잔차가 정규분포이다.
-> 정규성 검증 : shairo.test()
( p-value가 유의수준 0.05보다 작다 : 정규성을 만족하지 않는다. )
👀 로지스틱 회귀분석 (Logistic Regression)
- 비선형 가정으로 예측변수에 대하여 어떠한 분포의 가정도 필요하지 않음.
- 지도학습 중 분류 문제에 사용하는 알고리즘
- 분류하려는 범주(카테고리)가 2가지 범주로 나눠진 경우에 적용.
- 사건의 발생 가능성을 예측하는데 사용
👉 선형 회귀분석 → 로지스틱 회귀분석
- 선형 회귀 vs 로지스틱 회귀
: 선형 회귀는 " 10년 후 쌀 가격은 어떻게 될까요? "
( 연속형 데이터가 input → 연속형 데이터 output )
로지스틱 회귀는 " 10년 안에 쌀 가격이 50% 상승할까요? "
( 연속형 데이터가 input → 이산형 데이터 output )
- 예측하려는 y값을 A일 확률. y값(A일 확률)이 0.5 < A로 분류, 0.5 > B로 분류.
- 로지스틱 회귀분석은 x값이 -lnf ~ lnf 범위이며, y값의 확률이 0~1의 값이므로 y값을 -lnf ~ lnf로 변환시켜야 함.
① 선형 회귀식
y = ax + b
② y를 확률값 P로 변경
P = ax + b
( 여기서 P를 변형시켜 -lnf ~ lnf로 범위로 설정)
③ P 대신 오즈(Odds)

Odds = P/(1-P) = ax + b
④ 오즈(Odds) → 로그오즈(Log Odds)로 변경

⑤ e를 씌운다.

⑥ 역수를 취한다.

⑦ +1을 한다.
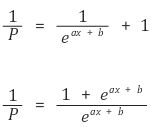
⑧ 다시 역수를 취한다.

-> 로지스틱 곡선이라고 함.

- 최적의 임계치 찾기
: 임계치는 Train Data를 기준으로 Validation Data를 넣어 잘 분류하는 임계치가 얼마인지 확인해서 정한다.
👉 로지스틱 회귀계수 추정 방법
1) 최대우도 추정(MLE)
- 표본 X로부터 우리가 알고자 하는 모수(파라미터)를 추정하는 법
- 우도(likelihood)는 확률분포에서 X가 발생했을 때, X가 나오게하는 파라미터의 가능성

- 즉, 파라미터 θ를 변화하며 표본 X에 대해 우도 L(θ)를 가장 최대화할 수 있는 θ를 찾는 것
- 우도 함수

- y: 종속변수 관측치
- p: 로지스틱 모형을 통해 나온 확률
-> 우도함수를 최대화하는 방법으로 회귀계수를 추정할 수 있으나, 최적의 해를 찾는다는 보장 x
- 우도비 검정 : 최우도법을 사용하므로 F-검정불가, 우도비 검정을 해야함.

- L(0) : 절편을 제외한 모든 계수가 0일 때의 우도함수의 최대값
- L(β) : 추정한 모형의 우도함수 값

- 0 < p² < 1 ( p² : 0.2~0.3일 때 우수한 모형)
'머신러닝' 카테고리의 다른 글
| 로지스틱 회귀분석 (Logistic Regression) (0) | 2023.06.08 |
|---|---|
| 머신러닝 - LightGBM (0) | 2023.04.19 |
| 더미변수 만들기 (0) | 2023.04.19 |
| 머신러닝 입문 (0) | 2023.04.19 |
| 머신러닝 Data Leakage (0) | 2023.04.18 |


