
빅데이터 전문가 되기
Python을 활용한 Crawling (네이버 뉴스) 본문
앞서, Python을 활용하여 지식백과를 Crawling을 하였습니다.
Python을 활용한 Crawling (네이버 지식백과)
키워드 검색을 통해 연관검색어, 검색어의 뜻에 대하여 알 수 있도록 지식백과를 Crawling해보겠습니다. 아래는 지식백과(naver)의 사이트 주소입니다. 지식백과 주소 : https://terms.naver.com/ 네이버 지
hi-210.tistory.com
이번에는 네이버 뉴스를 Crawling하여 이를 통해 Wordcloud를 해보겠습니다.
아래는 네이버 뉴스에 대한 주소입니다.
: 네이버 뉴스검색
''의 네이버 뉴스검색 결과입니다.
search.naver.com
앞서와 마찬가지로 이번에도 예시로 딸기를 키워드로 설정하겠습니다.

- 딸기에 대한 뉴스의 제목, 내용, 링크 주소를 가져오도록 하겠습니다.
👉 라이브러리 활성화
import urllib.request
# 검색어 인코딩
from urllib.parse import quote
from bs4 import BeautifulSoup

- 이번에는 전체의 내용을 가져온 후 그 안에서 for문을 활용하여 추출하겠습니다.
👉 함수를 활용하여 Crawling
def search(noun):
# 검색어를 ASCII로 인코딩
query = quote(noun)
url = f"https://search.naver.com/search.naver?where=news&sm=tab_pge&query={query}"
html = urllib.request.urlopen(url)
soup = BeautifulSoup(html, "html.parser")
hdline = soup.find("ul", {"class": "list_news"})
lis = hdline.findAll("li")
index = 1
for li in lis:
try:
a_tag = li.find("a", {"class": "news_tit"})
a_href = a_tag.get("href")
title = a_tag.get_text()
div_tag = li.find("div", {"class": "dsc_wrap"}).get_text().strip()
print("[" + str(index) + "]", title)
print(div_tag)
print(a_href)
index += 1
print()
except:
pass
noun = input("뉴스검색어를 입력하세요: ")
search(noun)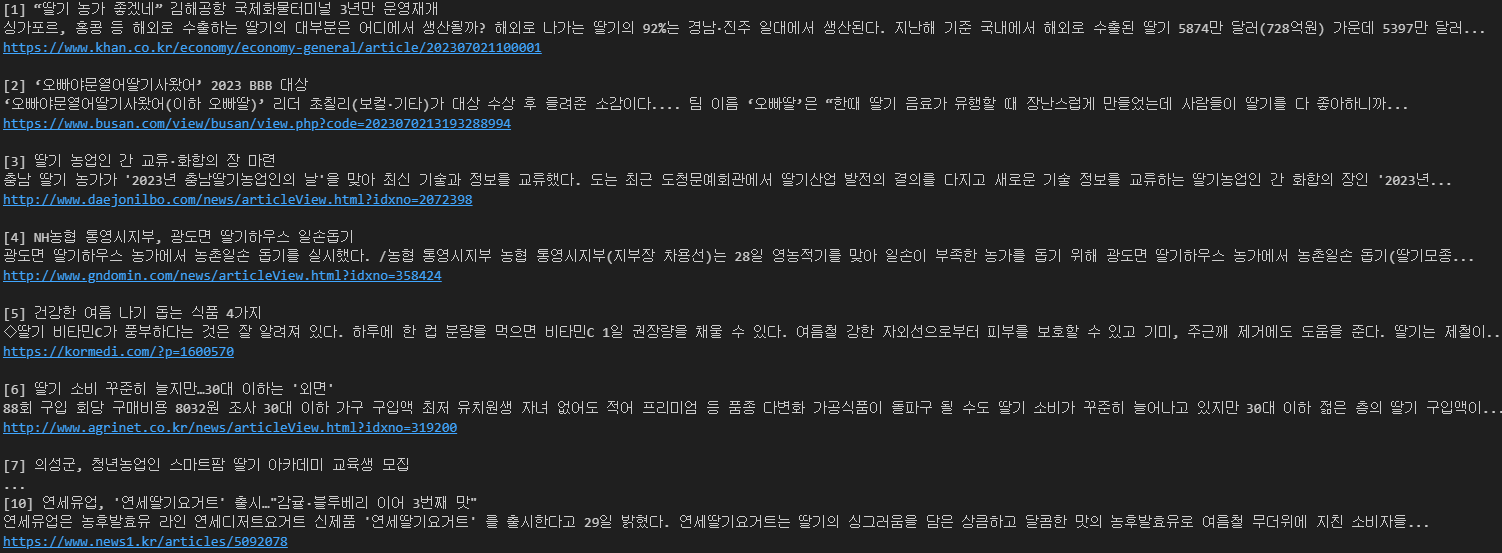
- 검색어를 아스키코드로 변경해줘야 하기 때문에 query의 변수를 넣어줍니다.
why? 사용자 정의함수로 설정을 해줬기 때문!
- for문을 활용하여 ul 안의 li를 가져옵니다.
- a, href, div의 내용을 text()만 가져오고 strip()으로 띄어쓰기를 제거해줍니다.
- try, except는 예외를 두어 에러의 발생을 방지합니다.
- 딸기에 대한 뉴스가 크롤링되는 것을 알 수 있습니다.
( 이는 한 페이지에 대한 내용만을 크롤링한 것으로 여러 페이지를 이용하고 싶으면 url을 변경해주면 됩니다. )
이상 네이버 뉴스 크롤링에 대한 설명이였습니다.
'Python' 카테고리의 다른 글
| OOP(Object Oriented Programming) (0) | 2023.07.04 |
|---|---|
| Crawling시 한글 깨짐 현상 해결 (0) | 2023.07.02 |
| Python을 활용한 Wordcloud (네이버 뉴스) (0) | 2023.07.02 |
| Python을 활용한 Crawling (네이버 지식백과) (0) | 2023.07.02 |
| Python을 활용한 구구단 만들기(for문) (0) | 2023.07.02 |


