
빅데이터 전문가 되기
z-test(z-통계량) 본문
😸 Z-통계량?
: 일반적으로 모집단의 평균에 대한 가설을 검정하는데 이용합니다. 표본 데이터를 사용하여 모집단의 평균에 대한 가설을 확인하고, 표본의 평균과 모집단의 평균이 유의미한 차이가 있는지 판단하는데 사용합니다.
- z 값

- SE (표준오차)


첫번째, 예시를 들어 설명하겠습니다.
- 2015년 대한민국 만 7세 여자 어린이의 평균키는 120cm 이다.
- 2020년 대한민국 만 7세 여자 어린이 30명의 평균 키는 125cm (표준편차 15) 일 때,
2020년 만 7세 여자 어린이의 평균키는 120cm로 볼 수 있는가?
- 가설을 설정하겠습니다.
- 귀무가설(H0) : 2020년 만 7세 여자 어린이의 평균키는 120cm이다.
- 대립가설(H1)
① 2020년 만 7세 여자 어린이의 평균키는 120cm가 아니다. : 제1형 (Two-Sided Test = Two Tailed Test)
② 2020년 만 7세 여자 어린이의 평균키는 120cm보다 작다. : 제2형 (One-Sided Test = Lower Tailed Test)
③ 2020년 만 7세 여자 어린이의 평균키는 120cm보다 크다. : 제3형 (One-Sided Test = Upper Tailed Test)
- Z-검정 통계량으로 구해보겠습니다.
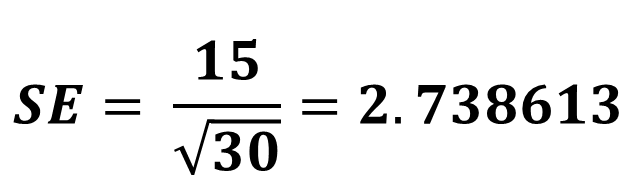

👉 시각화로 확인
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# 폰트에러
plt.rcParams['font.family']='sans-serif'
plt.rcParams['axes.unicode_minus']= False
# 주어진 값
n = 30 # 표본의 크기
standatd_error = 2.738613 # 표준오차
z_value = 1.825742 # z-통계량
# p-value 계산
p_value = 2 * (1- norm.cdf(abs(z_value)))
# z_value 값과 p_value 값 출력
print("z-value:", z_value)
print("p-value:", p_value)
# 그래프 그리기
x= np.linspace(-4, 4, 1000) # x 범위 설정
y= norm.pdf (x, 0, 1) # 표준 정규분포에서 확률밀도 함수 계산
plt.plot(x, y, 'b-')
plt.fill_between(x, 0, y, where=(x >=z_value), color='red', alpha=0.3)
plt.fill_between(x, 0, y, where=(x <=-z_value), color='red', alpha=0.3)
plt.xlabel('z-value')
plt.ylabel('Probability Density')
plt.title('Standard Normal Distribution with z-value')
plt.grid()
plt.show()
> z-value: 1.825742
> p-value: 0.06788913351512882
- p-value가 유의 수준(α =0.05) 이상이므로 귀무가설이 기각되지 않습니다.
- 즉, 귀무가설을 채택해야하므로, 만 7세 어린이의 키의 평균은 여전히 120cm라고 볼 수 있습니다.
두번째, 예시를 들어 설명하겠습니다.
- 모집단의 평균 : 67.5, 표준편차 : 9.5 일 때, 20명 심리학 학생 점수를 확인해보겠습니다.
- 20명의 평균은 67.5와 같은지 다른지 알아보겠습니다.
- 모집단의 수는 100개이며, 20명 심리학 학생의 점수는 50~89 사이라고 가정합니다.
- 가설을 설정합니다.
- 귀무가설 : 추출된 20개의 샘플의 평균은 67.5이다.
- 대립가설 : 추출된 20개의 샘플의 평균은 67.5이 아니다.
👉 데이터 불러오기
import pandas as pd
df = pd.read_csv("https://raw.githubusercontent.com/ethanweed/pythonbook/main/Data/zeppo.csv")
df.head()
👉 샘플의 평균 구하기
import statistics
statistics.mean(df['grades'])
> 72.3- 모집단의 평균은 67.5이고, 추출된 샘플의 평균은 72.3입니다.
- 모집단의 평균과 추출된 샘플의 평균은 다르게 봐야할까요? 오차의 범위로 봐야할까요?
👉 시각화 비교
- 전제 조건 : 샘플은 정규분포를 이루고 있습니다.
- 정규 분포의 확률 밀도 함수는 종 모양의 곡선이며, 곡선의 정점은 평균값(mu) 입니다.
- 표준편차 sigma는 곡선의 확산, 폭을 결정합니다.
import numpy as np
import seaborn as sns
from scipy import stats
from matplotlib import pyplot as plt
# 평균(mu), 표준편차(sigma)
mu= 0
sigma = 1
x = np.linspace(mu - 3*sigma, mu +3*sigma, 100)
y = 100*stats.norm.pdf(x, mu, sigma)
fig, axes = plt.subplots(1, 2, figsize=(15,5)
sns.lineplot(x=x, y=y, color='black', ax=axes[0])
sns.lineplot(x=x, y=y, color='black', ax=axes[1])
axes[0].set_frame_on(False)
axes[1].set_frame_on(False)
axes[0].get_yaxis().set_visible(False)
axes[1].get_yaxis().set_visible(False)
axes[0].get_xaxis().set_visible(False)
axes[1].get_xaxis().set_visible(False)
axes[0].axhline(y=0, color='black')
axes[0].axvline(x=mu + sigma, color='black', linestyle='--')
axes[1].axhline(y=0, color='black')
axes[1].axvline(x=mu + sigma, color='black', linestyle='--')
axes[0].hlines(y=23.6, xmin = mu-sigma, xmax = mu, color='black')
axes[1].hlines(y=23.6, xmin = mu-sigma, xmax = mu, color='black')
axes[0].text(mu, 42, r'$\mu = \mu_0$', size=20, ha='center')
axes[1].text(mu + sigma, 42, r'$\mu \neq \mu_0$', size=20, ha='center')
axes[0].text(mu-sigma - 0.2, 23.6, r'$\sigma = \sigma_0$', size=20, ha='right')
axes[1].text(mu-sigma - 0.2, 23.6, r'$\sigma = \sigma_0$', size=20, ha='right')
plt.show()
- 위 그림은 양쪽 그림 모두 분포가 동일하고 표준편차도 동일합니다.
- 단, 양쪽 그림의 평균은 다릅니다.
- z-score를 통해 얼마나 평균으로부터 떨어져 있는지 확인해보겠습니다.
👉 z-score
: 각 데이터 값이 평균으로부터 얼마나 떨어져 있는지를 나타내는 통계적인 예측값으로 표준화된 수치입니다.
import math
grades = df['grades']
sample_mean = statistics.mean(grades)
sample_mean
sd_true = 9.5
mu_null = 67.5
N = len(grades)
# 평균의 표준오차 구하기
sem_true = sd_true / math.sqrt(N)
print('표준오차:', sem_true)
# z_score 구하기
z_score = (sample_mean - mu_null) / sem_true
print('z_score', z_score)
> 표준오차: 2.1242645786248002
> z_score: 2.259605535157681👉 시각화 비교 (Two-Sided Test vs One-Sided Test)
mu = 0
sigma = 1
x = np.arange(-3,3,0.001)
y = stats.norm.pdf(x, mu, sigma)
fig, (ax0, ax1) = plt.subplots(1, 2, sharey = True, figsize=(15, 5))
# Two-sided test
crit = 1.96
p_lower = x[x<crit*-1]
p_upper = x[x>crit]
ax0.plot(x, y)
ax0.fill_between(p_lower, 0, stats.norm.pdf(p_lower, mu, sigma),color="none",hatch="///",edgecolor="b")
ax0.fill_between(p_upper, 0, stats.norm.pdf(p_upper, mu, sigma), color="none",hatch="///",edgecolor="b")
ax0.set_title("Two sided test", size = 20)
ax0.text(-1.96,-.03, '-1.96', size=18, ha="right")
ax0.text(1.96,-.03, '1.96', size=18, ha="left")
ax0.text(z_score, 0, 'O', size=18, ha="left", color = 'red')
# One-sided test
crit = 1.64
p_upper = x[x>crit]
ax1.plot(x, y)
ax1.set_title("One sided test", size = 20)
ax1.text(1.64,-.03, '1.64', size=18, ha="left")
ax1.fill_between(p_upper, 0, stats.norm.pdf(p_upper, mu, sigma), color="none",hatch="///",edgecolor="b")
ax0.set_frame_on(False)
ax1.set_frame_on(False)
ax0.get_yaxis().set_visible(False)
ax1.get_yaxis().set_visible(False)
ax0.get_xaxis().set_visible(False)
ax1.get_xaxis().set_visible(False)
plt.show()
- Two sided test (양측 검정)
① 가운데의 파란색 선은 표준 정규분포의 확률밀도 함수를 나타냅니다.
② 왼쪽 끝의 -1.96과 오른쪽 끝의 1.96은 95% 신뢰구간을 나타냅니다.
③ 빨간색 'O'는 검정 통계량(z-score)를 나타내며, 검정영역안에 있다는 것은 귀무가설을 기각할 수 있다는 뜻입니다.
- One sided tst (단측 검정)
① 오른쪽 끝의 1.64는 90% 신뢰구간을 나타냅니다.
② z-score가 음수이면 x가 평균보다 낮다는 것을 의미하고, z-score가 양수이면 x가 평균보다 높다는 것을 의미합니다.
- 마지막으로 p-value를 구해보도록 하겠습니다.
from statistics import NormalDist
lower_area = NormalDist()>cdf(-z_score)
upper_area = lower_area
p_value = lower_area + upper_area
p_value
> 0.023845743764939864
⇨ 결론 : p-value가 0.02로 유의수준 이하이므로 귀무가설을 기각하고 대립가설을 채택해야합니다.
따라서, 추출된 20개의 샘플의 평균은 67.5이 아니다라고 판단할 수 있습니다.
'통계' 카테고리의 다른 글
| 분산 분석(The Analysis of Variance) (0) | 2023.06.15 |
|---|---|
| 두 집단의 평균 비교 t-test(대응표본) (0) | 2023.06.15 |
| 두 집단의 평균 비교 t-test(독립표본) (0) | 2023.06.13 |
| One Sample t-test (0) | 2023.06.12 |
| 통계 관련 자료 모음 (0) | 2023.04.18 |


