
빅데이터 전문가 되기
[scikit-learn] Linear Models 본문
👀 선형 모델
: 대상 값이 기능의 선형 조합이 될 것으로 예상되는 회귀를 위한 일련의 방법
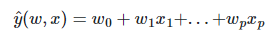
👉 일반 최소 제곱
: LinearRegression 계수가 있는 선형 모델에 적합 w = (w1,...wp) 데이터 세트에서 관찰된 대상과 선형 근사로 예측된 대상 사이의 잔차 제곱합을 최소화합니다.


LinearRegression 메서트 배열 X, y를 가져고오고 fit 계수를 저장합니다.
from sklearn import linear_model
reg = linear_model.LinearRegression()
# fit()메서드를 호출하여 모델 데이터에 맞춤
reg.fit([[0,0],[1,1],[2,2]],[0,1,2])
# coef_속성 사용 (데이터의 특징에 대한 가중치 포함)
## 각 특징이 출력 값에 얼마나 기여하는지 나타냄
reg.coef_
> array([0.5, 0.5])
👉 Ridge regression와 classification
: Ridge 회귀는 계수의 크기에 패널티를 부과하여 일반 최소 제곱의 일부 문제를 해결합니다. 능선 계수는 패널티가 적용된 잔차 제곱합을 최소화합니다.


메서드 배열 X, y를 Ridge 가져오고 fit 계수를 저장합니다.
from sklearn import linear_model
reg = linear_model.Ridge(alpha=.5)
reg.fit([[0,0],[0,0],[1,1]],[0,.1,1])
reg.coef_
> array([0.34545455, 0.34545455])
reg.intercept_
> 0.13636
- 정규화 매개변수 설정 ( leave-one-out Cross-Validation )
: RidgeCV알파 매개변수의 내장된 교차 검증으로 Ridge 회귀를 구현합니다. 객체는 기본적으로 leave-one-out cross-validation을 제외하고 girdsearchCV와 동일한 방식으로 작동합니다.
import numpy as np
from sklearn import linear_model
reg = linear_model.RidgeCV(alphas =np.logspace(-6,6,13))
reg.fit([[0,0],[0,0],[1,1]], [0,.1,1])
reg.alpha_
> 0.01cv 속성의 값을 지정하면 leave-one-out cross-validation이 아닌 10-fold cross-validation과 같은 gridsearchCV 교차 유효성 검사 사용이 트리거 됩니다. ( cv=10 )
👉 Lasso
: Lasso 희소 계수를 추정하는 선형모델입니다. 0이 아닌 계수가 적은 솔루션을 선호하는 경향으로 인해 일부 상황에서 유용하며 주어진 솔루션이 의존하는 기능의 수를 효과적으로 줄입니다. 이러한 이유로 Lasso와 그 변형은 압축 감지 분야의 기본입니다. 특정 조건에서 0이 아닌 계수의 정확한 세트를 복구할 수 있습니다.
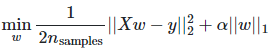
from sklearn import linear_model
reg = linear_model.Lasso(alpha=0.1)
reg.fit([[0,0],[1,1]],[0,1])
reg.predict([[1,1]])
> array([0.8])- alpha: 추정된 계수의 희소성 정도를 제어합니다.
- 교차 검증 사용 : 교차 검증을 통해 Lasso 매개변수를 설정하는 개체를 노출합니다. 공선형 기능이 많은 고차원 데이터 세트의 경우 LassoCV 가장 자주 사용됩니다. LassoLarsCV보다 관련성이 높은 매개변수 값을 탐색할 수 있는 장점이 있으며 alpha, 특징 수에 비해 샘플 수가 매우 적은 경우 보다 빠른 경우가 많습니다.

👉 MultiTaskLasso
: MultiTaskLasso는 다중 회귀 문제에 대한 희소 계수를 공동으로 추정하는 선형 모델입니다. y는 2D 배열입니다.
제약 조건은 선택한 기능이 작업이라고도 하는 모든 회귀 문제에 대해 동일하다는 것입니다.
Lasso 또는 MultiTaskLasso로 얻은 계수 행렬 W에서 0이 아닌 항목의 위치를 비교합니다. Lasso 추정치는 흩어져 있는 0이 아닌 값을 생성하는 반면 MultiTaskLasso의 0이 아닌 값은 전체 열입니다.


👉 Elastic-Net
: L1, L2 계수의 정규화로 학습된 선형 회귀모델입니다. Lasso와 같이 정규화 속성을 유지하면서 가중치가 0이 아닌 희소 모델을 학습할 수 있습니다. Elastic-net은 서로 상관 관계가 있는 여러 기능이 있을 때 유용합니다.
Lasso는 이들 중 하나를 무작위로 선택할 가능성이 높지만 Elastic-net은 둘 다 선택할 가능성이 높습니다.

👉 Multi-task Elastic-Net
: 다중 회귀 문제에 대한 희소 계수를 공동으로 추정하는 Elastic-net 모델입니다. y는 2D 배열입니다.
제약 조건은 선택한 기능이 작업이라고도 하는 모든 회귀 문제에 대해 동일하다는 것입니다.

MultiTaskElasticNet 클래스의 구현은 계수를 맞추는 알고리즘으로 좌표 강하를 사용합니다.
MultiTaskElasticNetCV alpha(a), L1_ratio의 교차-검증에 의해 클래스는 매개변수를 설정하는데 사용할 수 있습니다.
👉 Least Angle Regression (LARS)
: Bradley Efron, Trevor Hastie, lain Johnstone 및 Robert Tibshirani가 개발한 고차원 데이터용 회귀 알고리즘입니다.
LARS는 순방향 단계적 회귀와 유사합니다. 각 단계에서 대상과 가장 상관관계가 높은 기능을 찾습니다. 동일한 상관 관계를 갖는 여러 개의 기능이 있는 경우 동일한 기능에 따라 계속하는 대신 기능 간에 등각 방향으로 진행합니다.
👉 LARS Lasso
: LARS 알고리즘을 사용하여 구현된 올가미 모델이며, 좌표 하강에 기반한 구현과 달리 정확한 솔루션을 산출하며, 이는 해당 계수의 노름의 함수로서 조각별 선형입니다.
from sklearn import linear_model
reg = linear_model.LassoLars(alpha=.1)
reg.fit([[0,0],[1,1]],[0,1])
reg.coef_
> array([0.6, 0. ])
👉 Bayesian Regression (베이지안 회귀)
: 베이지안 회귀 기법을 사용하여 추정 절차에 정규화 매개변수를 포함할 수 있습니다. 정규화 매개변수는 딱딱한 의미로
설정되지 않고 현재 데이터에 맞춰 조정됩니다.
- Bayesian Ridge Regression

from sklearn import linear_model
X = [[0.,0.],[1.,1.],[2.,2.],[3.,3.]]
Y = [0.,1.,2.,3.]
reg = linear_model.BayesianRidge()
reg.fit(X,Y)
reg.predict([[1,0.]])
> array([0.50000013])
👉 Logistic Regression (로지스틱 회귀)
: 로지스틱 회귀는 명명법의 관점에서 회귀보다는 분류를 위한 선형 모델로 구현됩니다. 이 모델에서 단일 시도의 가능한 결과를 설명하는 확률은 로지스틱 함수를 사용하여 모델링 됩니다.
👉 Generalized Linear Models (GLM)
: 일반화 선형 모델은 선형 모델을 두 가지 방식으로 확장합니다. 먼저 예측값 y 입력 변수의 선형 조합에 연결됩니다.

분포의 확률 밀도 함수(PDF)의 그림입니다.

-> Poisson, Tweedie(power=1.5) 및 평균값이 다른 Gamma 분포를 따르는 랜덤 변수 Y의 PDF에서 점 질량을 관찰해보면
Y=0Poisson 분포 및 Tweedie 분포의 경우이지만 Gamma 분포의 경우에는 그렇지 않습니다.
- 분포 선택
- 목표가 y가 음이 아닌 정수이며, 상대 빈도(음이 아님)인 경우, log-link와 함께 Poisson distribution를 사용할 수 있습니다.
- 대상 값이 양수고 왜곡된 경우, log-link가 있는 Gamma distribution를 시도할 수 있습니다.
- 대상 값이 Gamma distribution보다 꼬리가 더 두꺼운 것처럼 보이면 Inverse Gaussan distribution (또는 Tweedie)를 시도할 수 있습니다.
- 목표 값이 y 확률이면 Bernoulli distribution를 사용할 수 있습니다. logit link가 있는 Bernoulli distribution은 이진 분류에 사용할 수 있습니다. softmax link가 있는 범주형 분포는 다중 클래스 분류에 사용할 수 있습니다.
- 사용 사례 예시
| 예 시 | Possion | Gamma | Tweedie/ Compound Possion Gamma |
| 농업/ 날씨 모델링 | 연간 강우 횟수 | 이벤트당 강우량 | 연간 총 강수량 |
| 위험 모델링 / 보험 정책 가격 책정 |
청구 이벤트 수 / 연간 보험 계약자 |
이벤트당 비용 | 연간 보험 계약자당 총 비용 |
| 예측 유지 보수 | 연간 생산 중단 이벤트 수 | 중단 기간 | 연간 총 중단 시간 |
| Bernouli | 사기 탐지 | 현금 이체와 같은 금융 거래가 사기 거래일 확률 |
| 신용 불이행 | 대출금을 갚지 못할 확률 | |
| 의료 약물 검사 | 일련의 시험에서 환자를 치료할 확률 or 환자가 부작용을 경험할 확률 |
- 사용법
: Tweedie 분포에 대한 일반화된 선형 모델을 구현하여 적절한 매개변수를 사용하여 위에서 언급한 분포를 모델링할 수 있습니다.
- power = 0 : Normal distribution (정규 분포)
( Ridge와 같은 특정 추정기가 ElasticNet 일반적으로 이 경우가 더 적합)
- power = 1 : Poisson distribution (푸아송 분포)
- power = 2 : Gamma distribution (감마 분포)
- power = 3 : Inverse Gaussian distribution (역가우스 분포)
link 기능은 link 매개 변수에 의해 결정됩니다.
from sklearn.linear_model import TweedieRegressor
reg =TweedieRegressor(power=1, alpha=0.5, link='log')
reg.fit([[0,0],[0,1],[2,2]],[0,1,2])
reg.coef_
> array([0.24631611, 0.43370317])
reg.intercept_
> -0.7638091359123443'Python > skcikit-learn' 카테고리의 다른 글
| [skcikit-learn] Cross Validation(교차 검증) (0) | 2023.04.28 |
|---|---|
| [scikit-learn] pipeline (0) | 2023.04.27 |

